by Riya Gohil
Technique Name: Chromatin Immunoprecipitation Sequencing (ChIP-seq)
Fun Rating: 3/5
Difficulty Rating: 4/5

What is the general purpose? Chromatin immunoprecipitation sequencing, or ChIP-seq, is used to identify protein-to-DNA interactions. It allows us to ‘look’ at where a protein of interest ‘sits’ on DNA.
Why do we use it? Proteins interact with DNA in unique ways. These protein-to-DNA interactions often affect gene expression by impacting whether a gene is “on” or “off.” Some protein-DNA interactions affect the level of expression of a particular gene while others affect how DNA is packaged or folded to fit inside the nucleus.
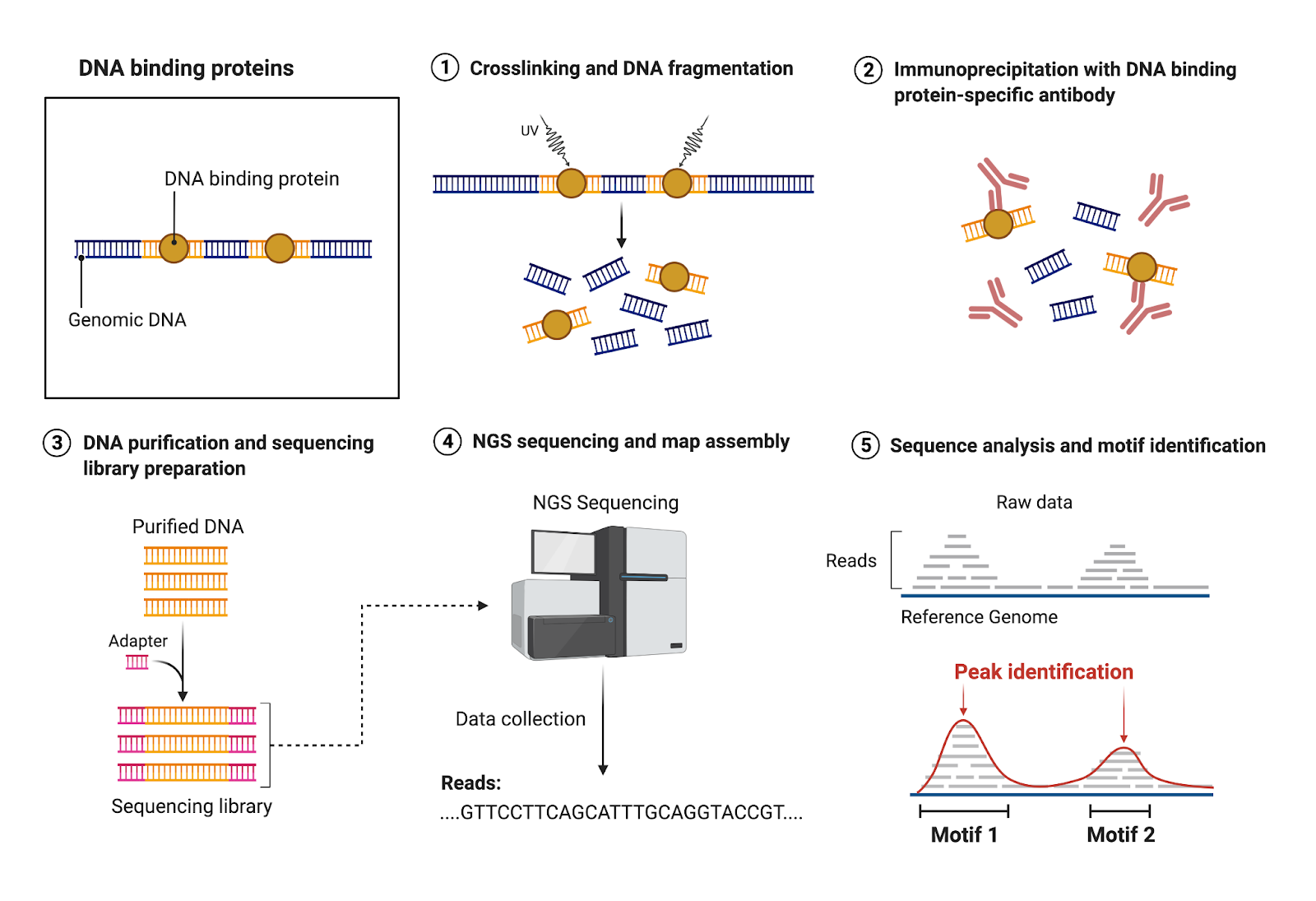
These protein-DNA interactions are very dynamic, with proteins binding and disengaging at various sites across the genome to regulate gene expression. However, most proteins bind to DNA at specific sites. Some examples of sites that proteins can bind to are gene enhancers and promoters as well as gene bodies (Figure 1). ChIP-seq allows scientists to identify those sites for individual proteins (Figure 2).
Knowing where a protein is interacting on the genome can give us information about how our protein of interest regulates DNA organization and gene expression and thus how our cells function.

How does it work?
- Crosslinking and DNA Fragmentation. To capture your protein of interest on the DNA, a crosslinking reagent such as formaldehyde is used to freeze the proteins on the DNA. Crosslinking allows for the formation of a covalent bond between proteins and DNA to stabilize their interaction.
DNA is an incredibly large molecule. Thus, the next step in ChIP-seq is to fragment the DNA into smaller pieces. This fragmentation step is essential for downstream sequencing because modern sequencing technologies can only sequence a few hundred base pairs at a time with good accuracy.
- Immunoprecipitation with antibody against protein of interest. Once the genome is fragmented into a more manageable size, an antibody specific to your protein of interest is added to the tube. This antibody is designed to specifically bind to your protein of interest and allows for isolation of that protein. All other proteins and unbound DNA will be washed away in a wash step. After this wash step, the material left in the tube is your protein of interest stuck to the DNA it binds.
- Reverse crosslinking, DNA purification, and sequencing library preparation. To enable sequencing, the next step is to use reverse crosslinking to “unglue” the antibody and protein from the DNA. The now unbound protein and antibody are washed off, leaving only the DNA sequences (purified DNA) that your protein of interest was bound to left in the tube. Small sequences called adaptors, which can be thought of as caps, are then added to the ends of the purified DNA to allow DNA to be recognized and sequenced on a sequencer. Once the adaptors have been added to the purified DNA, you now have a sequencing library, which can be sent off to a sequencing company.
- Next-generation sequencing (NGS) and map assembly. The company will run your libraries on a sequencer, a machine that takes your DNA fragments and reads the DNA sequence, giving you a list of all the sequences your protein was bound to.
- Sequence analysis and motif identification. The sequence data files you receive from the company can then be aligned to a reference genome, an intact genome of a particular species to provide an example to compare your data to. A reference genome allows you to map the location of the sequences in the genome. If your protein is frequently bound to a specific site, it is more likely that a larger portion of your library maps to the same site. This generates peaks, which represent sites that your protein binds to with specificity. Using special software, you can then identify what those sites (ex: genes, enhancers, etc).
Applications of ChIP-seq
ChIP-seq has been used to discover new universal and tissue-specific regulatory elements, such as enhancers and silencers. ChIP-seq has also been used to study epigenetic modifications, such as histone modifications, to provide insights on how the genome is organized. Not only is ChIP-seq useful for telling us something about the healthy functioning biology of our cells, it can also be used to gain a better understanding of various disease states. ChIP-seq has been used to identify the dysregulation of transcription factors, histone modifications, and other modulators of the genome that influence disease. For example, CTCF is a DNA binding factor that is a key regulator of genome organization and influences proper gene expression. Using ChIP-seq in healthy and diseased tissue, scientists can identify new and lost DNA binding sites of CTCF in cancer-specific tissues compared to healthy tissues. These new/altered interactions of CTCF with DNA in cancer-specific tissues have allowed scientists to study the impact of these binding events as a functional signature of cancer, changes in gene expression, changes in genome organization, and identification of new transcription factor binding events related to cancer. For instance, in T cell acute lymphoblastic leukemia, the transcription factor NOTCH1 has been shown to induce differential binding of CTCF to target activation of cancer-specific genes. Overall, the applications of ChIP-seq are vast and have provided a sort of lens into how different factors interact with DNA for cell function.
