by Hazel Milla
Fun Rating: 5/5

Difficulty Rating: 5/5
What is the general purpose?
Machine learning is a type of artificial intelligence (AI), which refers to the ability of computers to perform tasks that typically require human intelligence. To achieve this, programs are constructed from algorithms (sets of instructions) to perform tasks such as detecting patterns or making predictions. These programs, called machine learning models, learn from data without being explicitly trained to carry out these tasks.
Why do we use it?
Researchers often use machine learning methods to answer biological questions. There are two main types of machine learning methods: unsupervised and supervised.
In unsupervised learning, the model learns to detect patterns based on characteristics of the data (called features) that reflect unknown information (called labels). For example, scientists may want to determine what types of immune cells are in a blood sample based on the proteins those cells express. In this case, our features are protein expression levels, and the unknown labels are cell types. One common unsupervised method we can use for this task is clustering, whereby the model groups cells with similar protein expression patterns (Figure 1A). Researchers then examine these groups and label them as specific cell types, such as T cells or B cells, to estimate the quantity of each type.
In supervised learning, the model is trained using data with known labels (called ground truth labels). The model learns how features relate to these labels to make predictions on new data. For example, if the researchers already know the cell types present in a set of samples, they can train a model to recognize protein expression patterns that correspond to each cell type. Once trained, the model can predict cell type labels in a new sample based on protein expression data.
Machine learning can also be used to study people. For example, we might want to train a model to predict whether someone will develop coronary artery disease (CAD), a condition where arteries become blocked, reducing blood flow to the heart. If, in our dataset, we know who has CAD and who does not, we can use these ground truth labels to train our model. The model then learns patterns associated with disease risk based on biological information such as genetics, protein levels, and blood pressure (Figure 1B).
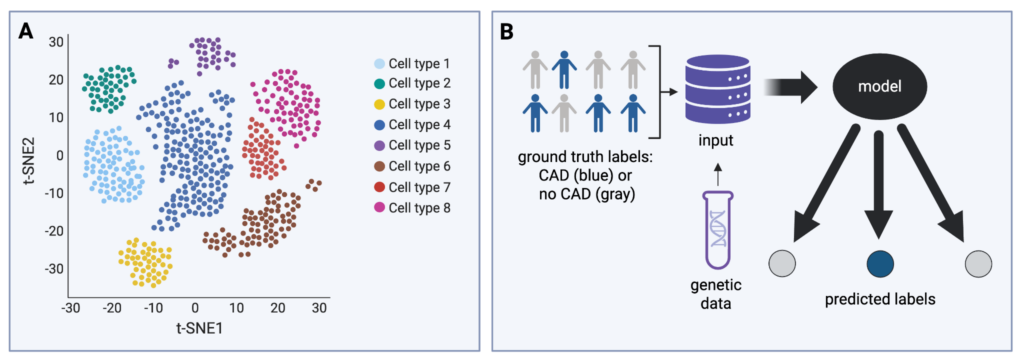
Figure 1. (A) Example of an unsupervised machine learning method: clustering. The labels on the x and y axes represent numbers generated by the t-SNE algorithm, which reduces high-dimensional data to two dimensions for visualization. The axes do not have direct biological meaning, but researchers can make inferences from the relative positions of data points. (B) Example of a supervised machine learning task. A model is trained to make predictions based on ground truth labels (CAD diagnosis) and biological information, such as genetic data. Figure created by the author using BioRender.
How does it work?
Step 1: Choosing a method
There are several machine learning techniques for different types of tasks. To predict whether someone has a disease, we might use a method like logistic regression, which estimates the probability that a person belongs to a category, such as having CAD or not, based on certain features.
Step 2: Developing the model
Training
First, we split our data into a training set and a validation set. In the training step, the model learns from data that includes both biological features (such as genetic data) and ground truth labels (CAD or no CAD). From this data, the model learns patterns and identifies parameters, which are numbers that help it make predictions.
Validation
After training, we test the model on the validation set and evaluate its performance. If it’s not accurately predicting CAD outcomes, we go back to the training step, adjust the model, and try again. Training and validation can be repeated several times until we are satisfied with the model’s performance.
Step 3: Testing the model
To ensure the model performs well on new data, we test it on a separate dataset not used during training or validation. This helps us check whether the model can generalize, meaning it works well beyond the data it was trained on.
Step 4: Implementing the model
Once the model performs well on the validation dataset, we can use it to make predictions in new data or derive biological insights–for example, identifying genes that may contribute to disease risk. The model could potentially help identify people at risk for CAD.
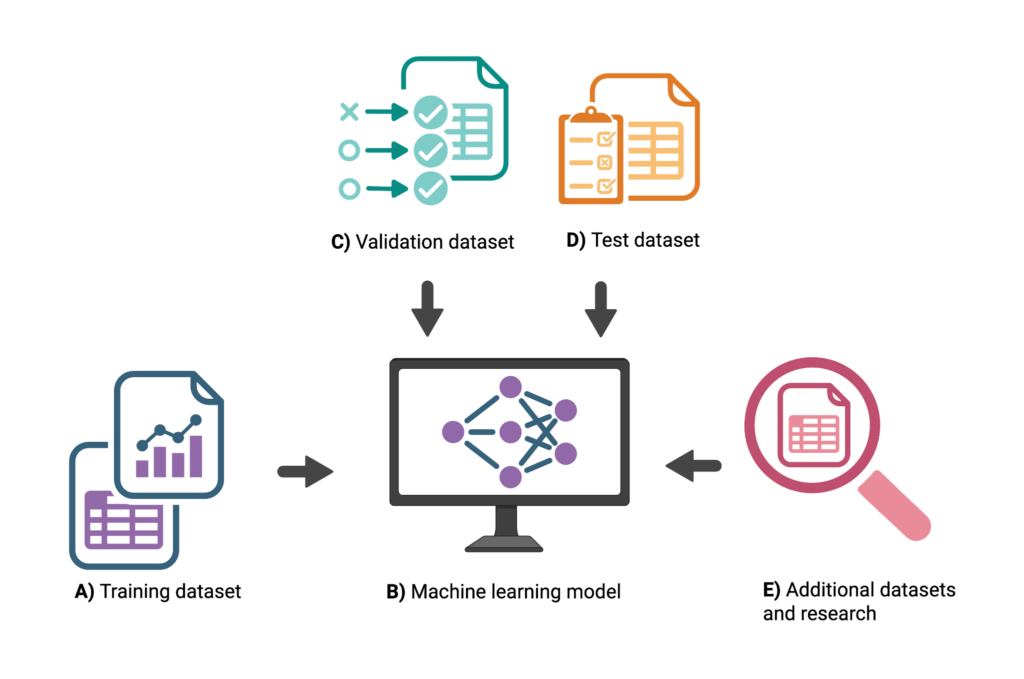
Figure 2: Supervised machine learning datasets and steps. A training dataset (A) is used to create a model (B). The model is optimized using a validation dataset (C) and evaluated using a test dataset (D). After these steps, the model can be applied to new datasets (E) for research purposes. Figure created by the author using BioRender.
Machine learning models can be powerful tools, but their usefulness depends on careful development and the use of diverse, high-quality data. When used effectively, machine learning can help scientists understand biological processes and improve predictions for outcomes such as disease. If you want to learn more about the ins and outs of this process, you can read about machine learning here, machine learning for biology here, and common pitfalls in machine learning here.
